4 Best Web Scraping Tools in 2026 ( Ranked By Performance, Stability & Price)
Finding the best web scraping tools can be surprisingly difficult. Over the past few months, I tested dozens of platforms while looking for reliable solutions for website data extraction, from simple free web scraping tools to advanced AI scraping tools designed for large-scale automation.
My goal was simple: find tools that can actually extract data from real websites without constantly breaking when facing JavaScript-heavy pages, CAPTCHAs, anti-bot protection systems, or IP blocking. If you’ve ever tried scraping modern websites, you already know that basic scraping software often fails when dealing with dynamic content, pagination, or complex page structures.
After spending hours testing different data scraping tools, running real scraping jobs, and comparing features like proxy support, automation workflows, structured data export, and scheduling, I found that only a handful of tools consistently performed well. Some were excellent for beginners who want easy no-code website data extraction, while others were powerful AI scraping tools built for developers and large-scale data collection.
In this guide, I’m sharing the 4 best web scraping tools I personally tested and compared. These tools stand out because they combine reliability, powerful scraping features, and flexible pricing—including several free web scraping tools that are surprisingly capable for small and medium scraping projects.
To make this comparison as useful and transparent as possible, I evaluated each tool using several practical criteria that matter when choosing the best web scraping tools for real-world use:
Bot protection handling: How well the tool deals with CAPTCHAs, rate limits, and modern anti-scraping systems
Scalability: Whether the tool can handle large-scale website data extraction across thousands of pages
Features: Support for proxies, JavaScript rendering, automation, APIs, and structured data export (CSV, JSON, Excel)
Ease of use: Learning curve, setup process, and documentation quality
Pros and cons: The real advantages and limitations I discovered during testing
Pricing: Availability of free plans, trials, and paid upgrades
Below, you’ll find my picks for the 4 best web scraping tools in 2026—including several powerful AI scraping tools that make website data extraction faster, easier, and far more reliable than traditional scraping methods.
Provider |
Start Trial |
Pricing/Monthly |
Ease of use |
Ratings |
|---|---|---|---|---|
5000 free credits | $49 | ⭐⭐⭐⭐⭐ | Trustpilot – 4.7 | |
50.000 free credits | $40 | ⭐⭐⭐⭐ | Trustpilot – 4.7 | |
1000 free credits | $29 | ⭐⭐⭐⭐⯨ | Trustpilot – 4.4 | |
100 free credits | $39 | ⭐⭐⭐⯨☆ | Trustpilot – N/A |
Table of Contents
The 4 Best Web Scraping Tools in 2026: In - Depth Review
Best for
Developers and businesses that need reliable large-scale website data extraction without managing proxies, browsers, or CAPTCHA systems.
Quick Summary (TL;DR)
If you don’t have time to read the full review, here’s a quick overview of ScraperAPI.
Feature |
Summary |
|---|---|
Best for | Developers and companies running large-scale web scraping |
Key strength | Automatic proxy rotation and CAPTCHA solving |
Ease of use | ⭐⭐⭐⭐⭐ |
Pricing model | Pay per successful request |
Ideal use cases | Ecommerce scraping, search engine data, competitive intelligence |
ScraperAPI Coupon Ccode (5%): SCRAPE13808195
Quick Verdict
After testing multiple best web scraping tools, ScraperAPI stood out as one of the most reliable solutions for automated data extraction.
It automatically handles proxy rotation, CAPTCHA solving, and anti-bot protection, allowing developers to focus on analyzing data rather than maintaining scraping infrastructure.
My Experience Using ScraperAPI
When I started testing platforms to find the best web scraping tools, I noticed that many tools perform well only on simple websites. Once you try scraping platforms with JavaScript rendering, anti-bot protection, or IP blocking, most tools begin to fail.
That’s where ScraperAPI really impressed me.
Instead of building a complex scraping infrastructure, I simply sent a request to the API and received raw HTML data from almost any website. ScraperAPI handled proxy rotation, CAPTCHA solving, and request retries automatically.
One feature I particularly appreciated was the automatic proxy management system. ScraperAPI maintains a massive proxy network with hundreds of thousands of IP addresses across multiple providers. Its smart routing system sends requests through different subnets, significantly reducing the risk of IP bans.
During testing, the platform also automatically throttled requests to avoid triggering anti-bot systems. Even when scraping websites that aggressively block bots, ScraperAPI maintained a high success rate without constant manual adjustments.
For developers building scraping workflows or companies collecting competitive intelligence, ScraperAPI essentially works as a complete scraping infrastructure in the cloud.
Key Features
Automatic Proxy Rotation
ScraperAPI manages a large proxy network and automatically rotates IP addresses to prevent blocking.
CAPTCHA Solving and Anti-Bot Bypass
The platform bypasses advanced anti-bot protections such as DataDome and PerimeterX.
Structured Data Endpoints
Pre-built endpoints provide clean structured data, reducing the time needed for parsing and data cleaning.
Smart IP Routing
Machine learning helps select the best proxy for each request.
Scalable Scraping Automation
Tools like Async Scraper and DataPipeline scheduling make it easy to run large scraping jobs.
Pricing
ScraperAPI uses a credit-based pricing model where you pay per successful request instead of bandwidth usage.
The number of credits depends on:
- The domain being scraped
- The level of anti-bot protection
- Additional parameters used in the request
For example, scraping ecommerce sites such as Amazon or Walmart typically costs 5 API credits per successful request.
Pros |
Cons |
|---|---|
|
|
How We Tested These Web Scraping Tools
To identify the best web scraping tools, we tested multiple platforms across real-world scraping scenarios.
Anti-bot bypass capability
We tested how well each tool handles CAPTCHAs, rate limits, and JavaScript-heavy websites.
Proxy reliability
We evaluated whether each platform provided reliable proxy rotation and stable scraping performance.
Scalability
Tools were tested on large scraping jobs to measure their ability to handle large-scale data extraction.
Ease of integration
We evaluated documentation, API usability, and implementation time.
Automation features
We tested scheduling tools, asynchronous scraping, and automation pipelines.
This testing process helped identify which tools truly deliver reliable AI-powered web scraping.
ScraperAPI Alternatives
While ScraperAPI is one of the best web scraping tools for developers, other platforms may be better depending on your use case.
Bright Data
Best for enterprise-level scraping and proxy networks.
Apify
Great for developers who want automation tools and pre-built scraping actors.
Octoparse
Ideal for beginners who prefer no-code web scraping.
ParseHub
Good option for visual scraping workflows and small projects.
Exploring these alternatives can help you find the right scraping solution.
Final Verdict
Overall, ScraperAPI is one of the best web scraping tools available for developers who want scalable and reliable website data extraction.
Its automatic proxy rotation, CAPTCHA solving, and powerful API make it ideal for both small scraping projects and enterprise-level data collection.
Best for
Developers, startups, and data teams that want a simple and affordable web scraping API with built-in proxy rotation, JavaScript rendering, and automated CAPTCHA handling.
Quick Summary (TL;DR)
If you don’t have time to read the full review, here’s a quick overview of Scrapingdog.
Feature |
Summary |
|---|---|
Best for | Developers and startups needing a simple scraping API |
Key strength | Affordable scraping infrastructure with proxy management |
Free trial | 1,000 free credits |
Ease of use | ⭐⭐⭐⭐ |
Pricing model | Credit-based (pay per request) |
Ideal use cases | SEO data scraping, ecommerce monitoring, AI datasets |
Quick Verdict
After reviewing several web scraping APIs, Scrapingdog stands out as a cost-effective scraping infrastructure that simplifies data extraction from websites.
The platform automatically handles rotating proxies, headless browser rendering, and CAPTCHA solving, allowing developers to collect HTML data from websites using a simple API call.
My Experience Using Scrapingdog
When testing different web scraping tools, I found that many platforms require developers to manage proxies, browser automation, and anti-bot systems manually.
Scrapingdog removes most of that complexity.
Instead of configuring scraping infrastructure, you simply send a request to the API and receive the HTML content of the target webpage. The platform handles the technical challenges like proxy rotation and JavaScript rendering behind the scenes.
During testing, one feature I particularly appreciated was the headless browser rendering capability. This allows Scrapingdog to properly load modern websites that rely heavily on JavaScript or lazy-loaded content.
The service also includes a global proxy pool, which rotates IP addresses automatically to avoid rate limits and blocking when scraping multiple pages.
Another useful capability is the platform’s parsed data endpoints. Instead of returning only raw HTML, some APIs deliver structured JSON data, which significantly reduces the amount of data cleaning required after scraping.
Overall, Scrapingdog works like a managed scraping infrastructure. Developers can focus on collecting and analyzing data instead of building and maintaining complex scraping systems.
Key Features
Rotating Proxy Network
Scrapingdog automatically rotates IP addresses from its proxy pool to prevent IP bans and rate limits when scraping websites.
JavaScript Rendering
The platform uses a headless Chrome browser to render JavaScript-heavy websites and load dynamic page content.
CAPTCHA Handling
Scrapingdog automatically handles CAPTCHA challenges so scraping requests can run without interruption.
Structured Data APIs
Some APIs return parsed JSON output, which helps developers extract structured data more efficiently.
Geotargeting
Requests can be routed through different geographic locations to scrape localized content.
Screenshot API
The platform can capture full-page screenshots of websites as part of the scraping process.
Pros |
Cons |
|---|---|
|
|
How We Tested These Web Scraping Tools
To evaluate the best web scraping APIs, we tested multiple platforms across real-world scraping scenarios.
Anti-bot bypass capability
We tested how effectively each tool handles anti-bot protections such as CAPTCHAs and IP rate limits.
Proxy reliability
Each platform was evaluated based on its ability to maintain stable scraping performance with rotating proxies.
JavaScript rendering
We tested whether the scraping tool could correctly extract content from dynamic websites.
Scalability
Large scraping tasks were performed to measure how well the platform handled high request volumes.
Ease of integration
APIs were evaluated based on documentation quality, implementation speed, and developer experience.
Scrapingdog Alternatives
Although Scrapingdog is a strong option for affordable scraping infrastructure, there are other web scraping APIs worth considering.
ScraperAPI – Great for developers needing scalable scraping infrastructure.
Bright Data – Enterprise-level scraping platform with a large proxy network.
Apify – Offers automation workflows and pre-built scraping actors.
Octoparse – Ideal for users who want a no-code web scraping solution.
Exploring these alternatives can help you find the best tool depending on your scraping needs.
Final Verdict
Overall, Scrapingdog is one of the most affordable web scraping APIs for developers who want a simple way to extract website data at scale.
Its rotating proxies, JavaScript rendering, and structured data APIs make it a practical solution for projects such as:
SEO data collection
Ecommerce price monitoring
AI dataset generation
Competitive intelligence
Best For
Crawlbase is best suited for:
developers building data pipelines
companies running large-scale web scraping
SaaS teams collecting market intelligence
eCommerce businesses doing price monitoring
If you want to avoid managing proxies and infrastructure yourself, Crawlbase can significantly simplify your scraping workflow.
Quick Summary (TL;DR)
Feature |
Summary |
|---|---|
Best for | Developers building scalable web scraping systems |
Core products | Crawling API, Smart AI Proxy, Crawler |
Free plan | 1,000 free credits |
Ease of use | ⭐⭐⭐⭐⯨ |
Pricing model | Credit-based requests |
Key strength | AI-powered proxy rotation + scraping infrastructure |
Crawlbase Review
If you’re looking for a reliable web scraping infrastructure that handles proxies, blocks, and scaling, Crawlbase is one of the most interesting platforms I tested while researching the best web scraping tools for developers.
Instead of forcing you to manage proxy pools, headless browsers, and anti-bot systems yourself, Crawlbase provides a complete scraping stack that includes:
- Crawling API
- Smart AI Proxy
- Rotating proxy infrastructure
- Cloud storage for scraped data
After testing several scraping APIs, I found that Crawlbase focuses heavily on developer-friendly scraping infrastructure, especially when dealing with sites that use bot protection or JavaScript rendering.
My Experience Using Crawlbase
When I first tested Crawlbase, the setup process was surprisingly simple.
Instead of building a full scraping infrastructure, I only needed to send requests through the Crawlbase API or Smart Proxy endpoint, and the system handled:
IP rotation
request retries
proxy infrastructure
JavaScript rendering
The biggest benefit here is that you don’t have to maintain your own scraping infrastructure.
For developers who have built scrapers before, this eliminates a huge amount of work like:
managing proxy pools
solving CAPTCHAs
maintaining headless browser clusters
Crawlbase essentially turns web scraping into an API request.
Key Crawlbase Features
1. Crawling API
Crawlbase provides a dedicated Crawling API designed for large-scale web scraping.
Instead of writing complex scraping logic, you can simply send requests to the API and receive the webpage data in response.
The platform also uses rotating proxies and AI infrastructure to improve success rates when scraping websites.
Some benefits include:
Request-based pricing
Infrastructure built for large scraping workloads
Reduced maintenance compared to DIY scraping
For startups and data teams, this can significantly reduce the engineering time required to maintain scraping systems.
2. Smart AI Proxy
Another core feature is the Smart AI Proxy network.
Instead of manually managing proxies, Crawlbase routes requests through a pool of rotating IPs before reaching the target website.
Key capabilities include:
Rotating proxy infrastructure
JavaScript rendering support
Custom geolocation
Unlimited bandwidth
AI-optimized request routing
The proxy system uses machine learning techniques to reduce blocks and CAPTCHA issues, making scraping more reliable.
This is especially useful for scraping:
eCommerce sites
search engines
price monitoring platforms
market research datasets
3. Large Proxy Infrastructure
Crawlbase’s Smart AI Proxy includes access to a large proxy pool.
For example, some plans provide:
100,000 unique proxies
10,000 rotating IP addresses
mixed datacenter and residential proxies
This helps maintain high scraping success rates when collecting data from websites that actively block bots.
4. JavaScript Rendering Support
Many modern websites rely heavily on JavaScript.
Crawlbase supports JavaScript rendering directly within requests, allowing the scraper to collect data from dynamic pages.
JavaScript requests typically consume more credits than standard requests because they require additional processing.
5. Cloud Storage for Scraped Data
Crawlbase also provides built-in cloud storage for scraped content.
This allows you to automatically save and access responses from the Crawling API without building your own storage infrastructure.
This feature is useful for teams running large scraping pipelines or data extraction workflows.
Crawlbase Pricing
Crawlbase uses a credit-based pricing model based on request usage.
You only pay for successful requests, which helps reduce unnecessary costs.
Pricing characteristics include:
1 credit per standard request
2 credits for JavaScript rendering requests
free requests available when signing up
This usage-based pricing model makes Crawlbase flexible for both:
small scraping projects
enterprise-level data extraction
Pros |
Cons |
|---|---|
|
|
Final Verdict
Overall, Crawlbase is a powerful platform for developers who want a scalable web scraping infrastructure without managing proxies or crawler systems manually.
With features like:
Crawling API
Smart AI Proxy
rotating IP infrastructure
JavaScript rendering
it provides a complete stack for building data extraction pipelines.
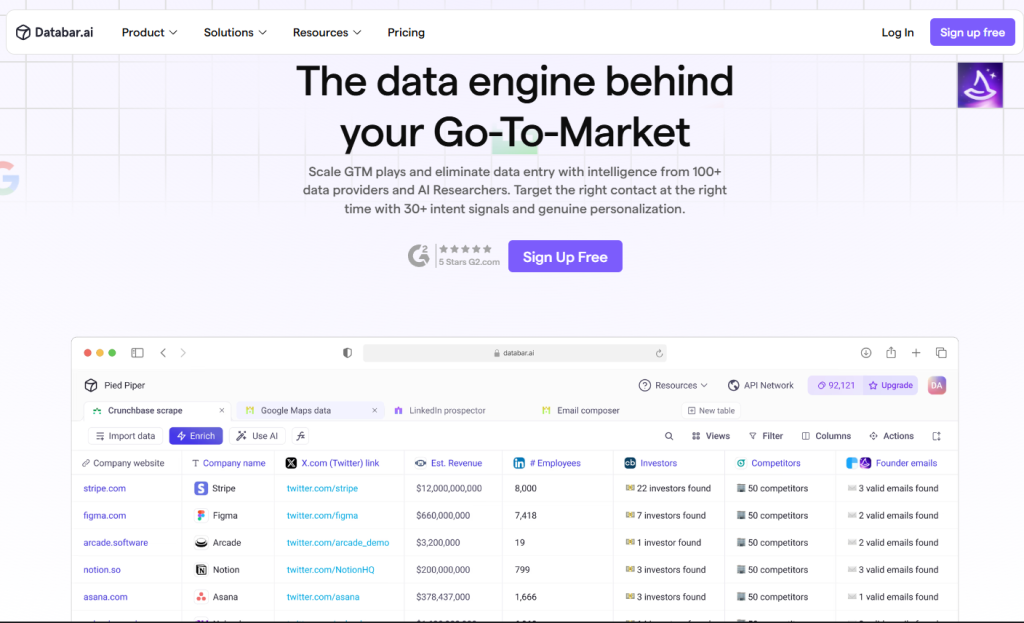
Quick Summary (TL;DR)
Feature |
Summary |
|---|---|
Best for | Marketers, sales teams, and analysts who want no-code web scraping and data enrichment |
Key Strength | Spreadsheet-style interface + hundreds of data sources |
Free plan | 1,00 free credits |
Ease of use | ⭐⭐⭐⯨☆ |
Pricing | Paid plans starting around $39/month |
Web Scraping | AI-powered scrapers + Chrome extension |
Databar.ai Coupon Ccode (5%): FRIENDSOFDATABAR
Databar.ai Review
My Experience Using Databar.ai
When I first tested Databar.ai, what stood out immediately was how different it feels compared to traditional web scraping tools.
Instead of writing code, managing proxies, or building complicated scraping scripts, Databar works more like a smart spreadsheet that fills itself with data.
You start by importing a list of companies, websites, or contacts — and then simply choose the data you want to enrich. Within seconds, the platform automatically pulls additional information from multiple sources.
For example, I tested a simple workflow where I uploaded a list of company websites. Databar automatically enriched them with details like founders, company information, and other business data points — all inside a spreadsheet-like interface.
What surprised me the most is that the entire process requires no coding at all.
The platform integrates with 100+ data providers, allowing you to enrich datasets with hundreds of additional attributes.
This makes Databar particularly useful for:
lead generation
market research
sales prospecting
business intelligence
data enrichment workflows
Instead of manually gathering data from dozens of sources, Databar essentially turns your spreadsheet into an automated data engine.
Why Databar.ai Is Different
Most web scraping tools are built primarily for developers.
Databar takes a completely different approach.
It focuses on making APIs, data providers, and web scraping accessible without technical knowledge.
The platform comes with pre-configured scrapers and connectors, so users don’t need to manage proxies, write scripts, or maintain scraping infrastructure.
In practice, this means you can:
scrape websites
enrich business datasets
connect external APIs
automate recurring data workflows
—all from a simple interface that looks similar to Google Sheets.
For many teams, this removes the biggest barrier to web scraping: technical complexity.
Key Features
No-Code Web Scraping
One of the main features of Databar is its ability to scrape web data automatically without code.
Users can create custom web scrapers in just a few minutes. The platform handles the configuration and infrastructure behind the scenes.
Instead of building a scraper manually, you simply:
Choose a data source
Configure your collector
Run or schedule the scraper
Databar then extracts the structured data for you.
100+ Data Provider Integrations
Databar connects to over 100 data providers, allowing you to enrich datasets with additional insights.
For example, you can add:
company data
contact information
financial metrics
social signals
intent data
All enrichments can be applied directly inside your workspace.
3. AI-Powered Data Enrichment
Databar allows users to enrich datasets with over 450 data points by combining multiple sources automatically.
One of the most powerful features is Waterfall Enrichment, which queries multiple providers at once to maximize data coverage.
This means the platform automatically falls back to alternative data sources when one provider doesn’t return results.
4. Chrome Extension for Instant Scraping
Databar also offers a Chrome extension that can extract data from any website in just two clicks.
This makes it extremely convenient for quick data collection.
Once scraped, the data can be automatically sent to your Databar workspace for enrichment and analysis.
5. Automated Data Workflows
The platform allows users to schedule data pipelines and automations.
Scrapers and enrichments can run automatically on a schedule — every minute, daily, weekly, or monthly.
This makes Databar useful for:
recurring research tasks
sales prospecting pipelines
automated reporting
CRM data synchronization
Pros |
Cons |
|---|---|
|
|
Who Should Use Databar.ai
Databar is ideal for teams that want web scraping and data enrichment without building their own infrastructure.
It works especially well for:
marketers building lead lists
sales teams enriching prospect data
analysts gathering market intelligence
startups automating research workflows
Developers can still use Databar through its REST API, Python SDK, or CLI for programmatic workflows.
Databar.ai Alternatives
If Databar doesn’t fit your use case, here are some alternatives often used for web scraping:
ScraperAPI (developer-focused scraping API)
Crawlbase (proxy + scraping infrastructure)
ScrapingDog (web scraping API with proxy rotation)
However, most of these tools require significantly more technical setup compared to Databar.
Final Verdict
Databar.ai is one of the most interesting tools in the web scraping ecosystem because it combines web scraping, data enrichment, and API automation into a single platform.
Instead of forcing users to manage scraping infrastructure, proxies, and scripts, Databar focuses on making data collection simple and accessible.
For teams that want to automate research, lead generation, or business intelligence workflows without writing code, Databar is definitely worth trying.
Final Verdict: Which Web Scraping Tool Should You Choose?
After testing multiple platforms and comparing their features, it’s clear that each web scraping tool serves a different type of user. The best option ultimately depends on your technical skills, scale of scraping, and automation needs.
Here’s the quick breakdown.
Best AI Web Scraping Tool → ScraperAI
If your goal is to automate scraping with AI-powered workflows, ScraperAI is the most interesting option.
Instead of building complex scraping scripts, the platform focuses on AI agents that automatically extract and structure website data.
Best for:
AI-driven web scraping workflows
automated research tasks
extracting structured data with minimal setup
👉 Best choice if you want AI to handle the scraping logic.
Best No-Code Web Scraping Tool → Databar.ai
If you’re a marketer, sales team, or analyst, Databar.ai is one of the easiest tools to use.
Its spreadsheet-style interface allows you to scrape websites and enrich datasets without writing code.
The platform also connects to 100+ data providers, making it powerful for lead generation and data enrichment workflows.
Best for:
no-code web scraping
sales prospecting
data enrichment
automated research workflows
👉 Best choice if you want web scraping without coding.
Best Web Scraping API for Developers → ScraperAPI
If you’re a developer building large-scale scraping infrastructure, ScraperAPI is one of the most reliable platforms.
It handles the hardest parts of scraping automatically:
proxy rotation
CAPTCHA solving
anti-bot bypass
JavaScript rendering
All through a simple API request.
Best for:
developers building scrapers
large-scale data extraction
ecommerce price scraping
search engine scraping
👉 Best choice if you need high-volume scraping infrastructure.
Best Crawling Infrastructure → Crawlbase
If your project requires web crawling infrastructure and proxy networks, Crawlbase is a strong option.
It provides APIs that allow developers to crawl and extract data from websites while bypassing bot protection systems.
This makes it particularly useful for projects that require continuous data collection at scale.
Best for:
large-scale crawling
proxy infrastructure
automated website data extraction
👉 Best choice if you need reliable crawling infrastructure.
Scrapingdog vs Competitors